




























Diffusion Explorations 011: Video to Origami
February 21, 2024: Two explorations using AnimateDiff and IPAdapter to convert video to a papercraft origami style.
I created this video in collaboration with Karen X Cheng:
Side-by-side showing original. Karen used Instagram Giphy stickers to guide the AI animation:
Another video to papercraft exploration using skating footage:
I tried different input images for IPAdapter to create different looks:
IPAdapter input image applied to source.
Alternate IPAdapter input image

Finally, I also tried stylizing this video using a snowy felt image:
Diffusion Explorations 010: Video Cartoon Stylization using AnimateDiff and IPAdapter
December 1, 2023: A short experiment to stylize video with minimal flickering. I created an IPAdapter image for each shot based on a style developed by Paul Trillo as research for short film project about Carl Sagan's Golden Record.
Input video is 30fps iPhone footage shot before school one morning and the result is rendered at 10fps.
Input & Result below. Full-screen result is here.
Sample IPAdapter input Images:
Sample style explorations and background removal:



Diffusion Explorations 009: AI VFX: Motion Inpainting
November 21, 2023: These examples use masks and in-painting with AnimateDiff to modify a still image or moving video using a text prompt.
Created in collaboration with Paul Trillo. These clips are also available individually on this Notion page.
Moving Video Inpainting: Six examples in this video:
Still Image Motion Inpainting: This technique can also be used with still images to add motion to them, like cinemagraphs and similar to RunwayML’s Motion Brush. Some short examples:
Sample input image, matte, and results:





Diffusion Explorations 008: AI VFX: QR Monster ControlNet In Motion with AnimateDiff
October 6, 2023: This combines a simple logo animation created in After Effects (left) and AnimateDiff with the QR Monster controlnet into a loop. We can drive complex motion from a simple animation and control the look through only a prompt.
A variation prompting “hot ash” instead of water:
Diffusion Explorations 007: Text to Animation (Prompt Travel) using AnimateDiff
October 3, 2023: This exploration uses AnimateDiff to generate and animate between keyframed text prompts to create cel-style animation.
DNA helix, sand dunes, ocean waves, coastline, mountains, continent, planet, galaxy, passageway, atom.
Diffusion Explorations 006: Video to Animation using AnimateDiff
September 30, 2023: AI-generated animation from a video. This experiment combines video of a dance performance by Erica Klein and Hok and a text prompt to stylize it. Music by Nic Dematteo of Equal Music.




Diffusion Explorations 005: Gen1 and Stable Diffusion to Stylize Video
Aug 9, 2023: An experiment with Paul Trillo, Hok, and Erica Klein to turn a video of dance choreography into smoke.
Input sequence and result:
Diffusion Explorations 004: ControlNet and Stable Diffusion to Modify Images
Feb 20, 2023: Initial experiments using ControlNet to modify images with Stable Diffusion via the Automatic1111 WebUI.
Picasso sketches modified with Controlnet Scribble Model:



Input: Sketch of San Francisco Skyline

Variations generated with ControlNet - Including regular SD 1.5 model and custom fine-tuned model based on woodcuts dataset:














Input: Watercolor of Lakeshore Ave in Oakland

Generated Variations:






Diffusion Explorations 003: Fine Tuning Diffusion Models
May 18, 2022: Experiments fine-tuning OpenAI’s Guided Diffusion on new datasets. Starting with LSUN bedroom 256 checkpoint and then showing the AI new datasets. Below are some generated samples as well as charts showing training progression.
Cubism Finetune, CLIP-Guided with various prompts:

Diffusion Gender Study v1 showing the same seed with a different CLIP prompt.

Diffusion Gender Study v2 showing the same seed with a different CLIP prompt.








Figure Drawing Fine Tune, CLIP-guided with various prompts:




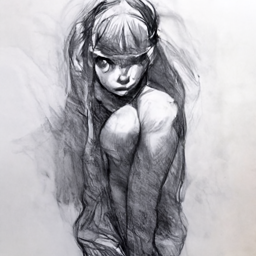














Guided Diffusion, fine tuned on figure drawings, CLIP-guided.
Beeple Fine Tune
Here I am trying to answer the question, “How long to fine tune a diffusion model?” using a dataset of Beeple’s everydays. (The same dataset used in my BeepleGAN explorations below.)
Comparing CLIP guidance on 256 unconditional model with Beeple fine-tuned model:

“A sphere from the future” - Beeple fine tuned model.

“A sphere from the future”, 256 Unconditional Model
Additional diffusion fine tuning charts comparing number of trainings steps / iterations:
CLIP-guided Diffusion Fine Tuning training progression


Diffusion Explorations 002: Disco Diffusion Portraiture
February 15, 2022: Experiments creating portraits using Disco Diffusion.
Text Prompt Only:






Init Image and results:




Baby Cacti!






Diffusion Explorations 001: CLIP Portraiture
October 5, 2021: Experiments creating portraits with CLIP-guided diffusion notebooks created by Katherine Crowson and Daniel Russell. Some with an init image, some without, all have a text prompt.
Init Self Portrait


More Variations:








GAN Explorations 018: Music Video for Arrival by Hiatus
November 13, 2020: A collaboration with London-based Hiatus (Cyrus Shahrad) for the single Arrival off his upcoming album, Distancer.
Inspired by the lyrics and personal meaning of Rumi's poem, The Guest House, Cyrus and I developed a GAN model based on a custom dataset of micro and macro imagery of cells, galaxies and other forms representing the building blocks of humanity and it's own place in the universe.
The visuals show a connection between our thoughts and elemental selves - even down to our individual cells - and the larger universe which seems so other, so alien and outside of us, yet which is made of exactly the same stuff, and came from exactly the same place.
Cyrus created intentional edits through our hybrid cell & stars model by arranging thumbnails which then provided the locations in latent space to interpolate through.
The video:
Also featured in an article on UK independent new music website, The Line Of Best Fit:

“The track commences with throbbing electronica that acts like a strong heartbeat as the soft spoken delivery of The Guest House poem begins. The mellow recital of the poem adds a soothing tone to the pensive, pulsing electronica, before Hiatus introduces subtle piano and faint ethereal electronica to slowly build a sense of hope as the poem progresses.
Hiatus gradually incorporates euphoric electronica and builds on the beat to elevate the hopeful tone of the song, which is projected like a fluttering heartbeat.”
Cyrus was able to create intentional edits based on thumbnails of generated star and cell images. He created thumbnail edits where the imagery morphs from the small to the large.
Thumbnail edit and resulting video:
Above: Sequence of 9 images that drive a GAN animation (right).
We also explored different ways of generating our model. Below are some early tests where two separate models, one of cells and one of stars, are blended using stochastic weight averaging.
Model blending stills and animation:
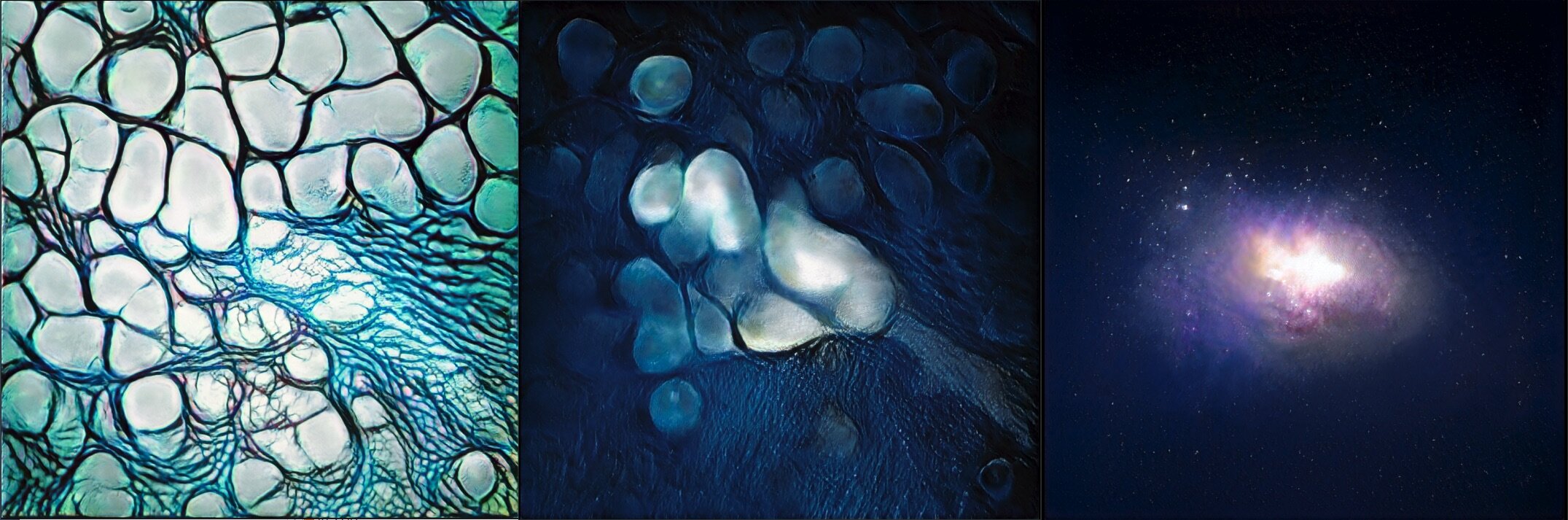
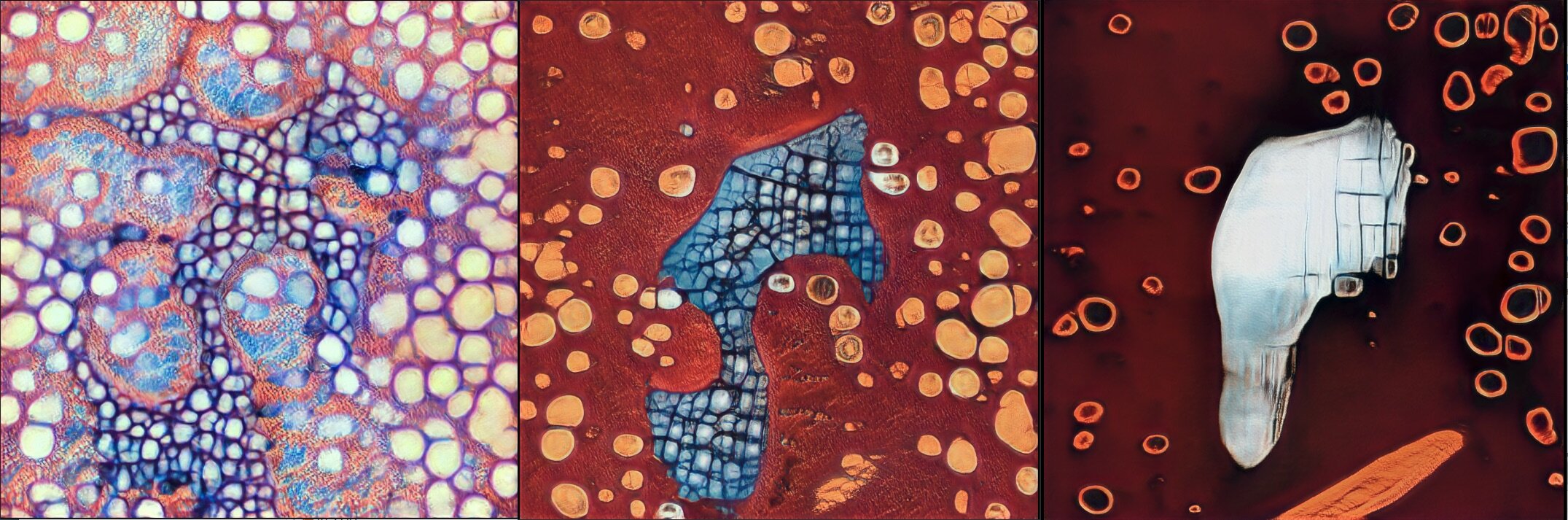


Finally, here are some other samples of imagery we created during our exploration:




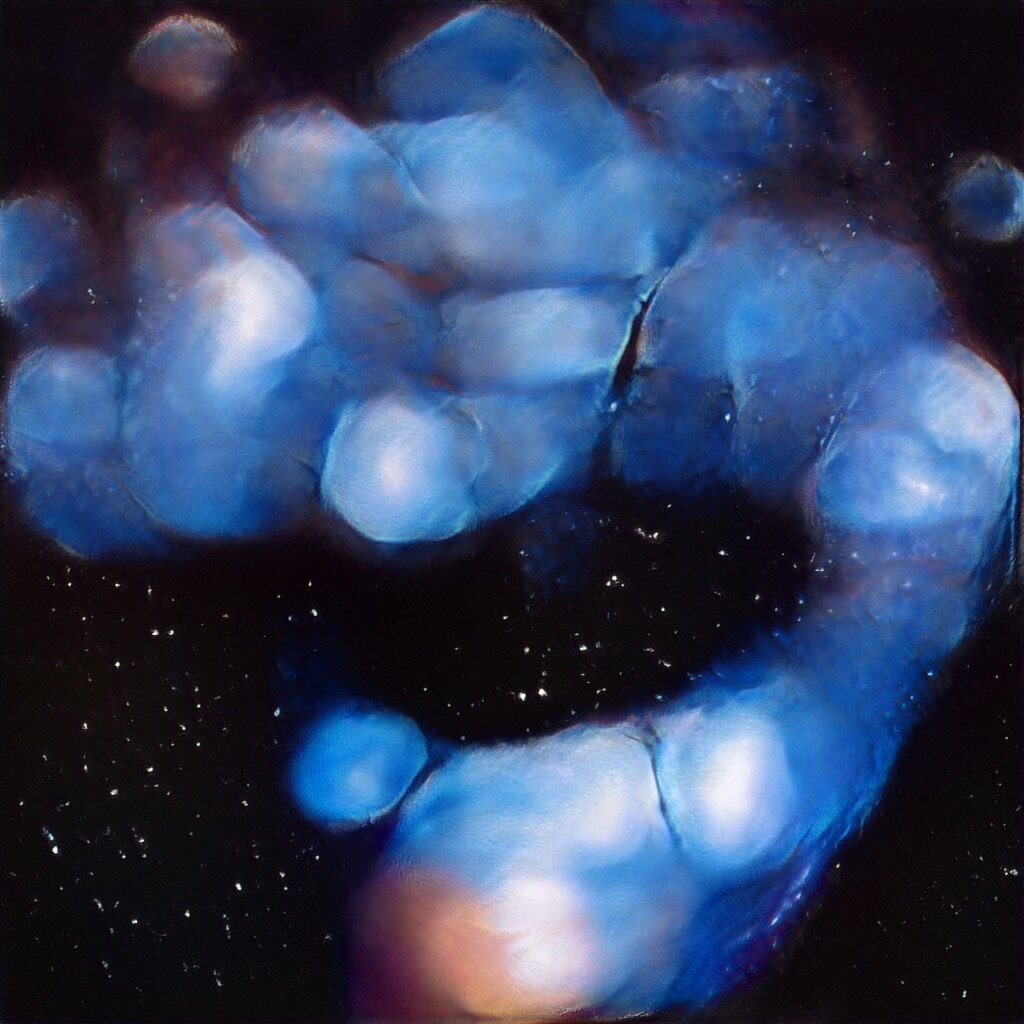



GAN Explorations 017: Character Sketches to Real People
October 22, 2020: Using character sketch time lapses as input for the pixel2style2pixel framework. Three example videos:
GAN Explorations 016: Reverse Toonification / Real Versions of Paintings & Cartoons
October 13, 2020: Creating the real person versions of paintings and cartoons with Elad Richardson and Yuval Alaluf’s pixel2style2pixel.
Some samples. Click to enlarge:







GAN Explorations 015: Toonifying Faces using Layer Blending in StyleGAN
September 21, 2020: Using and expanding on the work of Justin Pinkney and Doron Adler, I’ve been experimenting with creating cartoon versions of human faces and stylizing them using ArtBreeder.
The FFHQ model is fine-tuned on a dataset of cartoon faces and that resulting model is blended with the initial FFHQ model. Low level layers that control overall face shape (eye size, etc) are taken from the cartoon model. Layers that control finer detail are taken from the realistic FFHQ model.
Here are some sample images showing source, tooned, and stylized:





Additionally, I’ve been trying to answer the question: "What's the 'best' way to toonify a face?" so I built a new dataset and models to look at the results of more/less training and blending at different layers. Here’s one of cartoon President Obama:
Comparing more transfer learning time (right).
Some additional results of toonifying other celebrities:




Here are some results of animating a toonified Uma Thurman using the First Order Motion model and video from TikTok:
GAN Explorations 014: Two Hour BeepleGAN Loop
July 14, 2020: Two hours of interpolating through the latent space of BeepleGAN. Dataset is Beeple’s Everydays.
GAN Explorations 013: Standalone Raspberry Pi GAN Player
June 24, 2020: I put together a stand-alone generative art player showing the results of early StyleGAN training I did in 2019. It only does one thing: endlessly loops on a Raspberry Pi with built-in 4" screen. A commissioned piece.
Video and Stills:




GAN Explorations 012: Aesop’s Fables Woodcut Illustrations
February 6, 2020: What does it look like for a computer create art informed by 15th-century woodcut illustrations? In these examples, images were scanned by Brady Baltezore from Aesop: Five Centuries of Illustrated Fables, published in 1964 by the Metropolitan Museum of Art.
The book:



Sample book imagery:






Generated Images:
The model trained on the Aesop Images was transfer trained from my own WikiArt dataset.


Results Interpolation Video:
A 1-minute animated loop exploring the woodcut results.
Additional Generated Images:








Original StyleGAN Version with Blob Artifacts:
I originally attempted training with this dataset in November, 2019 before StyleGAN2 was released. The blob artifacts made the results unusable:

GAN Explorations 011: StyleGAN2 + Stochastic Weight Averaging
January 29, 2020: Explorations using Peter Baylie’s stochastic weight averaging script. A new, average model is created from two source models. The sources in this case are based on WikiArt imagery and Beeple’s art. Each source is transfer-learned from a common original source.
Basically, it’s a fast way to blend between two StyleGAN models!
Left Image: WikiArt
Middle Image: Average
Right Image: Beeple











GAN Explorations 010: StyleGAN2
January 6, 2020: Some still images from the StyleGAN2 implementation of #BeepleGAN.





GAN Explorations 009: StyleGAN2
December 14, 2019: Nvidia released StyleGAN2. The blobs are gone! Here are some early results of training with Beeple’s everyday imagery.
First a video:

Some generated stills:




GAN Explorations 008: Qrion Album Art
November 26, 2019: Created generative visualizer videos for the release of Qrion’s Sine Wave Party EP out on Anjunadeep. The artist, Momiji Tsukada, curated a set of images she associates with the music. I took these and created audio-reactive, generative videos. These are some of my favorite still images I created during the training process:








GAN Explorations 007: Embedding Imagery
November 5, 2019: Building upon BeepleGAN HQ, here is an exploration of embedding intentional imagery (the number “5”) into the output of the model. In this way, I’m able to control and specify what the output looks like rather than just taking whatever random output the model produces.
Results video:
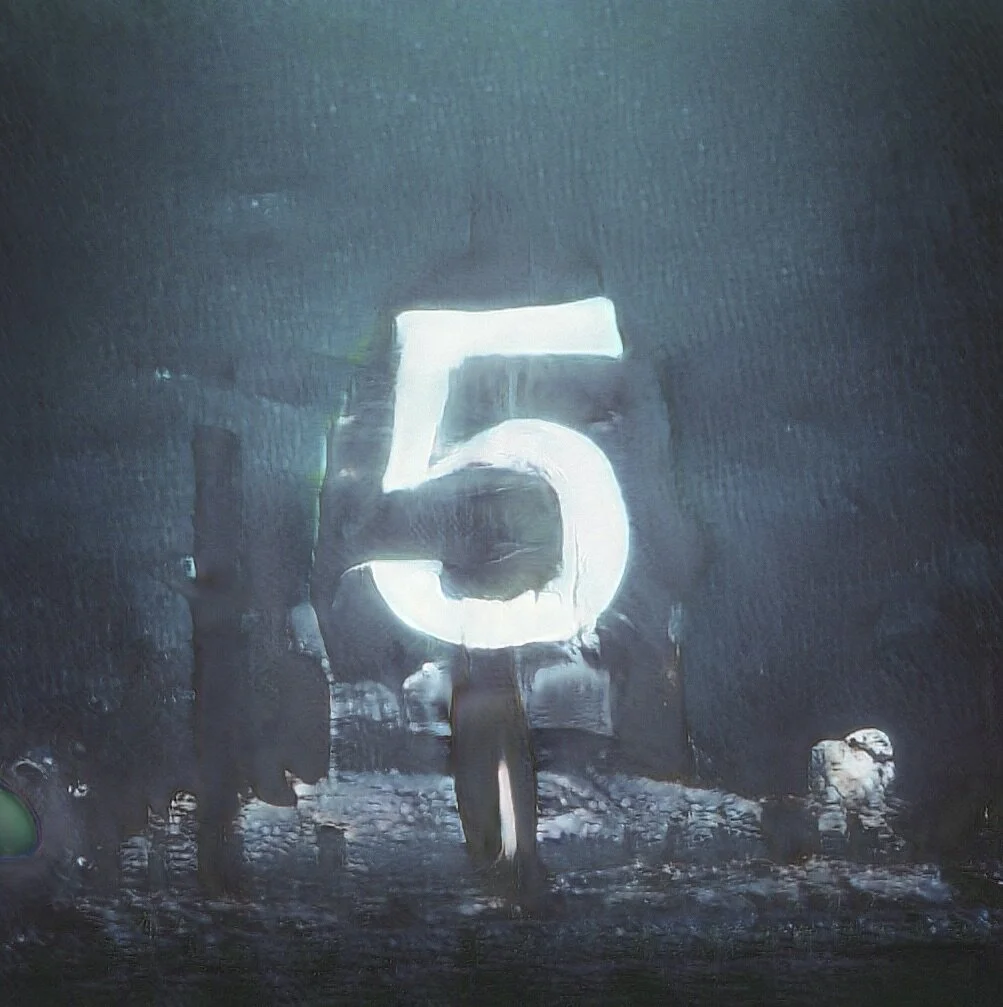
Still frames:



GAN Explorations 006: BeepleGAN HQ
October 28, 2019: BeepleGAN goes HD. 1024x1024. Holy moly.




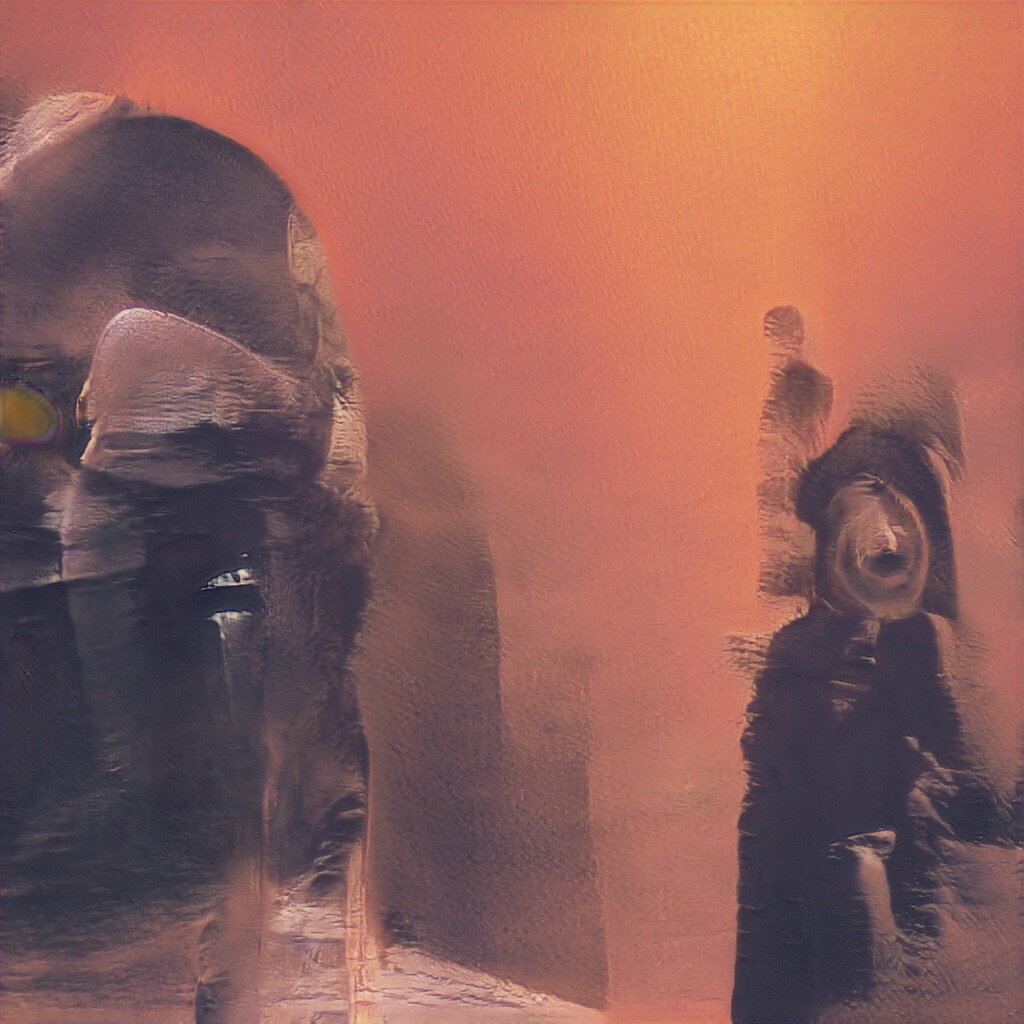





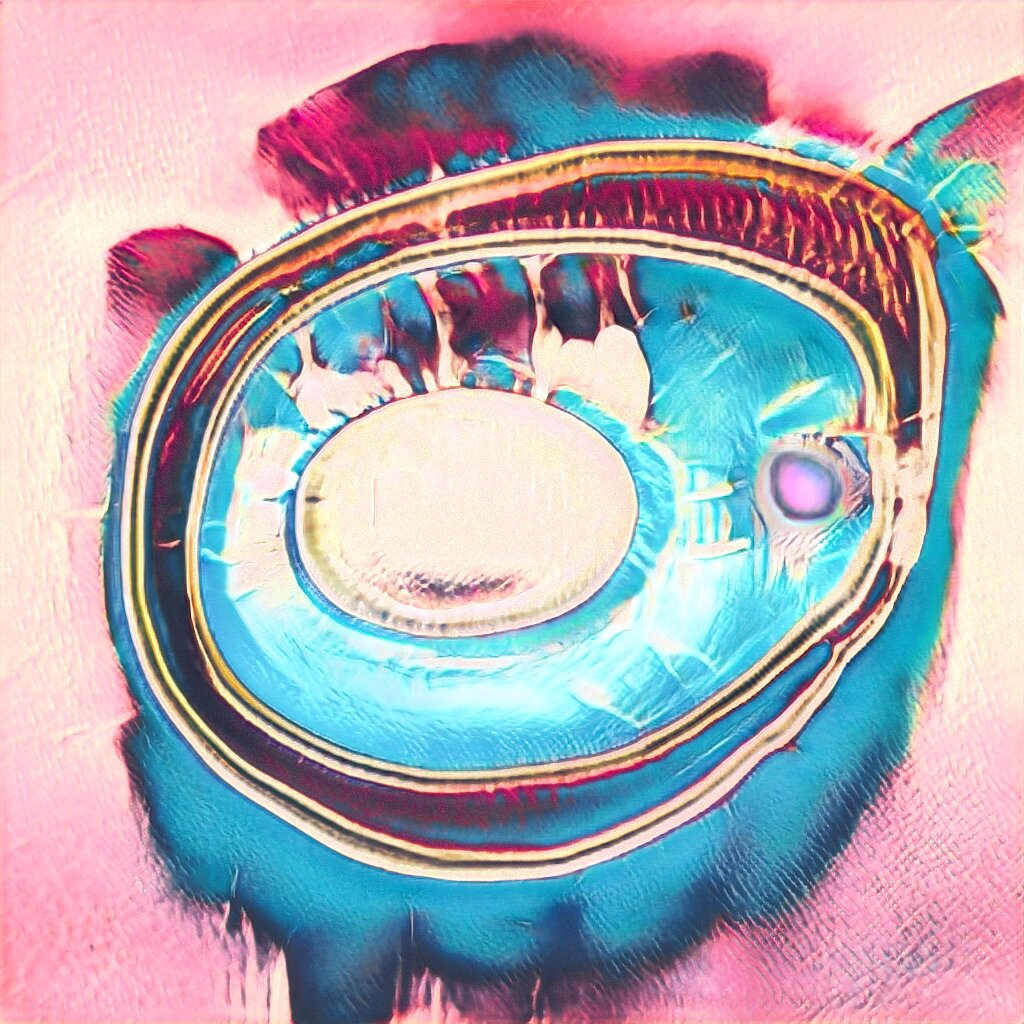



GAN Explorations 005: BeepleGAN
October 25, 2019: Learning from Beeple’s Everydays.








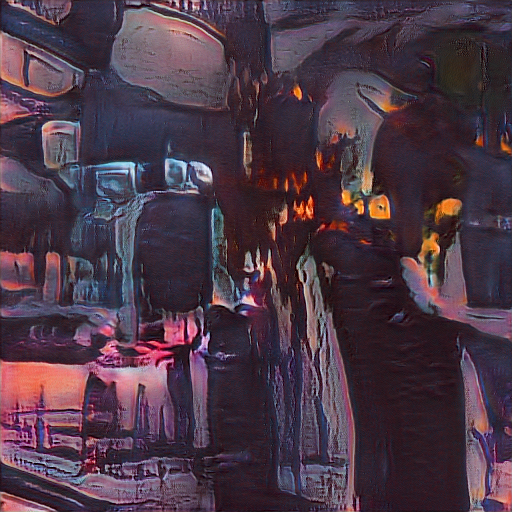








GAN Explorations 004: Cubism Transfer Learning
October 24, 2019: Image on the left is generated by /u/_C0D32_’s WikiArt.org model.
Image on the right shows that same latent vector after being trained on a custom dataset of cubist imagery.

A generated image versus it’s Cubist representation in the parallel model, followed by more examples:




GAN Explorations 003: PopArtGAN
October 21, 2019: Results of training StyleGAN from scratch on a custom dataset of Pop Art imagery.
A video:

A selection of stills:

GAN Explorations 002: Figure Drawing / Pop Art Diptychs
October 17, 2019: Results of transfer learning a model trained on WikiArt.org (from /u/_C0D32_) with both figure drawings and pop art. Diptychs feature the same random vector interpolation through the two parallel models.
Video:

Stills:





GAN Explorations 001: Figure drawings + the history of art as understood by a neural network.
October 16, 2019: Results of combining two StyleGAN neural networks - the first trained on a broad sampling of art (WikiArt.org), and the second a transfer learning from a small, custom dataset of figure drawings.
Video:

Sample images from varying truncation Ψ:







Acknowledgments and Inspiration
Thanks go to:
Gwern Branwen for their incredible guide to working with StyleGAN.
Reddit user /u/_C0D32_ for sharing their work with WIkiArt imagery and StyleGAN.
Josh Urban Davis for inspiration and guidance.
Maryam Ashoori for transfer learning inspiration.
Memo Akten for inspiration with his project, Deep Meditations.
Code modified from NVIDIA Research Projects official StyleGAN GitHub repo.